基于云計算技術的ChatGPT服務器搭建 裝備、技術與實踐
隨著人工智能技術的飛速發展,以ChatGPT為代表的大型語言模型在自然語言處理、智能問答、內容創作等領域展現出巨大潛力。其強大的能力背后是對計算資源的極高要求,這使得基于云計算技術的服務器搭建方案成為企業部署和運行這類模型的主流選擇。本文將探討基于云計算技術搭建ChatGPT服務器的關鍵裝備、技術服務與實施路徑。
一、 云計算基礎設施裝備
搭建支撐ChatGPT這類大型模型推理的服務器集群,首先需要依托云服務商提供的高性能基礎設施。核心裝備要求包括:
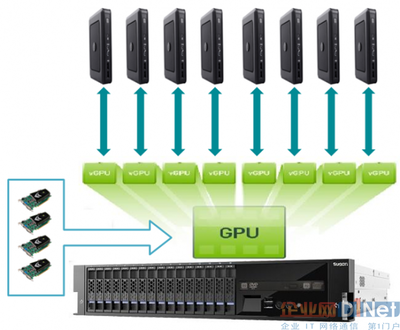
- 計算資源:必須配備具備強大并行計算能力的GPU實例,例如NVIDIA的A100、H100或V100 Tensor Core GPU。云服務商(如AWS EC2 P4/P5實例、Azure NC/ND系列、Google Cloud A2/A3 VM)提供了專門針對AI工作負載優化的虛擬機,能夠提供每秒萬億次浮點運算的算力。
- 存儲系統:模型文件(通常數百GB)和大量訓練/交互數據需要高速、可擴展的存儲。這包括高性能的云塊存儲(如SSD)用于系統盤和臨時數據,以及對象存儲服務(如AWS S3、Azure Blob Storage)用于持久化存儲模型檢查點和數據集。
- 網絡架構:模型加載、多GPU并行計算以及高并發用戶訪問都依賴低延遲、高帶寬的網絡。云服務商通常提供高達100Gbps甚至更快的實例間網絡,并可通過虛擬私有云(VPC)和負載均衡器構建安全、高效的網絡環境。
二、 核心技術與服務棧
在硬件之上,一系列軟件技術和云服務構成了服務器運行的大腦與神經。
- 容器化與編排:使用Docker將ChatGPT模型、推理引擎及其依賴環境打包成容器鏡像,確保環境一致性與可移植性。通過Kubernetes(或云托管的K8s服務,如EKS、AKS、GKE)進行容器編排,實現服務的自動部署、彈性伸縮和高可用管理。
- 模型部署與優化框架:利用諸如NVIDIA Triton Inference Server、TensorRT或PyTorch Serve等專用推理服務器框架,對模型進行優化(如量化、剪枝),以降低延遲、提高吞吐量并減少資源消耗。
- 云原生服務集成:
- 安全與監控:集成云身份與訪問管理(IAM)、密鑰管理服務(KMS)保障安全,利用云監控(如CloudWatch、Azure Monitor)和日志服務追蹤性能指標與運行狀態。
- 自動伸縮:根據GPU利用率、請求隊列長度等指標,配置自動伸縮策略,在流量高峰時自動擴容實例,低谷時縮容以優化成本。
- API網關與流控:通過API網關(如Amazon API Gateway)對外提供統一、安全的API接口,并實施速率限制和配額管理。
三、 搭建實踐與技術服務流程
實際搭建過程是一個系統工程,通常遵循以下步驟,并可借助云服務商或第三方提供的專業技術服務:
- 需求分析與方案設計:明確預期并發用戶數、響應延遲要求、預算等,選擇合適的云區域、實例規格和架構(如是否采用多節點分布式推理)。
- 環境準備與資源配置:在云平臺創建VPC、子網、安全組,申請GPU實例,掛載存儲,配置網絡。
- 模型準備與容器化:獲取或微調ChatGPT模型,編寫推理API代碼,創建Dockerfile并構建鏡像,推送至容器鏡像倉庫(如ECR、ACR)。
- 部署與配置:編寫Kubernetes部署(Deployment)、服務(Service)等配置文件,部署至集群。配置持久化存儲卷、網絡策略、資源限制等。
- 集成與測試:配置負載均衡器與API網關,集成監控告警系統。進行壓力測試和功能驗證,確保服務穩定。
- 運維與優化:持續監控性能,根據日志分析問題,優化模型和配置。利用云成本管理工具分析支出,調整實例類型或使用競價實例等策略以優化成本效益。
四、 挑戰與展望
盡管云計算提供了強大的彈性和便利,搭建此類服務器仍面臨挑戰:高昂的GPU實例成本、模型推理的延遲優化、多租戶環境下的安全隔離等。隨著云計算服務與AI技術的深度融合,預計將出現更多針對大模型優化的專屬實例、更高效的推理芯片以及更智能的自動化運維服務,使得大規模AI服務的部署變得更加經濟、高效和便捷。
基于云計算技術搭建ChatGPT服務器,是企業將尖端AI能力轉化為穩定、可擴展服務的有效途徑。它不僅僅是將模型“放上云”,更是一個深度融合了高性能計算、云原生架構和智能運維的綜合性技術工程。
如若轉載,請注明出處:http://m.saishai.cn/product/83.html
更新時間:2026-04-06 09:08:47